Over the last several months, Dropbox has been undertaking an overhaul of its internal search engine for the first time since 2015. Today, the company announced that the new version, dubbed Nautilus, is ready for the world. The latest search tool takes advantage of a new architecture powered by machine learning to help pinpoint the exact piece of content a user is looking for.
While an individual user may have a much smaller body of documents to search across than the World Wide Web, the paradox of enterprise search says that the fewer documents you have, the harder it is to locate the correct one. Yet Dropbox faces of a host of additional challenges when it comes to search. It has more than 500 million users and hundreds of billions of documents, making finding the correct piece for a particular user even more difficult. The company had to take all of this into consideration when it was rebuilding its internal search engine.
One way for the search team to attack a problem of this scale was to put machine learning to bear on it, but it required more than an underlying level of intelligence to make this work. It also required completely rethinking the entire search tool from an architectural level.
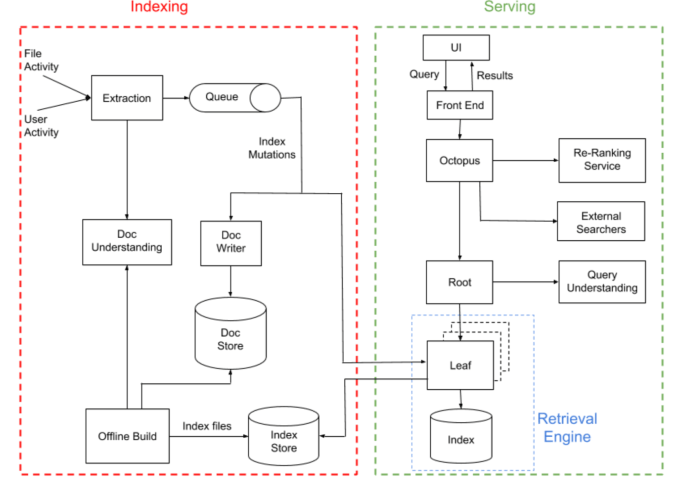
That meant separating two main pieces of the system, indexing and serving. The indexing piece is crucial of course in any search engine. A system of this size and scope needs a fast indexing engine to cover the number of documents in a whirl of changing content. This is the piece that’s hidden behind the scenes. The serving side of the equation is what end users see when they query the search engine, and the system generates a set of results.
Nautilus Architecture Diagram: Dropbox
Dropbox described the indexing system in a blog post announcing the new search engine: “The role of the indexing pipeline is to process file and user activity, extract content and metadata out of it, and create a search index.” They added that the easiest way to index a corpus of documents would be to just keep checking and iterating, but that couldn’t keep up with a system this large and complex, especially one that is focused on a unique set of content for each user (or group of users in the business tool).
They account for that in a couple of ways. They create offline builds every few days, but they also watch as users interact with their content and try to learn from that. As that happens, Dropbox creates what it calls “index mutations,” which they merge with the running indexes from the offline builds to help provide ever more accurate results.
The indexing process has to take into account the textual content assuming it’s a document, but it also has to look at the underlying metadata as a clue to the content. They use this information to feed a retrieval engine, whose job is to find as many documents as it can, as fast it can and worry about accuracy later.
It has to make sure it checks all of the repositories. For instance, Dropbox Paper is a separate repository, so the answer could be found there. It also has to take into account the access-level security, only displaying content that the person querying has the right to access.
Once it has a set of possible results, it uses machine learning to pinpoint the correct content. “The ranking engine is powered by a [machine learning] model that outputs a score for each document based on a variety of signals. Some signals measure the relevance of the document to the query (e.g., BM25), while others measure the relevance of the document to the user at the current moment in time,” they explained in the blog post.
After the system has a list of potential candidates, it ranks them and displays the results for the end user in the search interface, but a lot of work goes into that from the moment the user types the query until it displays a set of potential files. This new system is designed to make that process as fast and accurate as possible.
from Enterprise – TechCrunch https://ift.tt/2OUhPi8
via https://ifttt.com/ IFTTT
No comments:
Post a Comment