For any company built on top of machine learning operations, the more data they have, the better they are off — as long as they can keep it all under control. But as more and more information pours in from disparate sources, gets logged in obscure databases and is generally hard (or slow) to query, the process of getting that all into one neat place where a data scientist can actually start running the statistics is quickly running into one of machine learning’s biggest bottlenecks.
That’s a problem Intermix.io and its founders, Paul Lappas and Lars Kamp, hope to solve. Engineers get a granular look at all of the different nuances behind what’s happening with some specific function, from the query all the way through all of the paths it’s taking to get to its end result. The end product is one that helps data engineers monitor the flow of information going through their systems, regardless of the source, to isolate bottlenecks early and see where processes are breaking down. The company also said it has raised seed funding from Uncork Capital, S28 Capital, PAUA Ventures along with Bastian Lehman, CEO of Postmates, and Hasso Plattner, Founder of SAP.
“Companies realize being data driven is a key to success,” Kamp said. “The cloud makes it cheap and easy to store your data forever, machine learning libraries are making things easy to digest. But a company that wants to be data driven wants to hire a data scientist. This is the wrong first hire. To do that they need access to all the relevant data, and have it be complete and clean. That falls to data engineers who need to build data assembly lines where they are creating meaningful types to get data usable to the data scientist. That’s who we serve.”
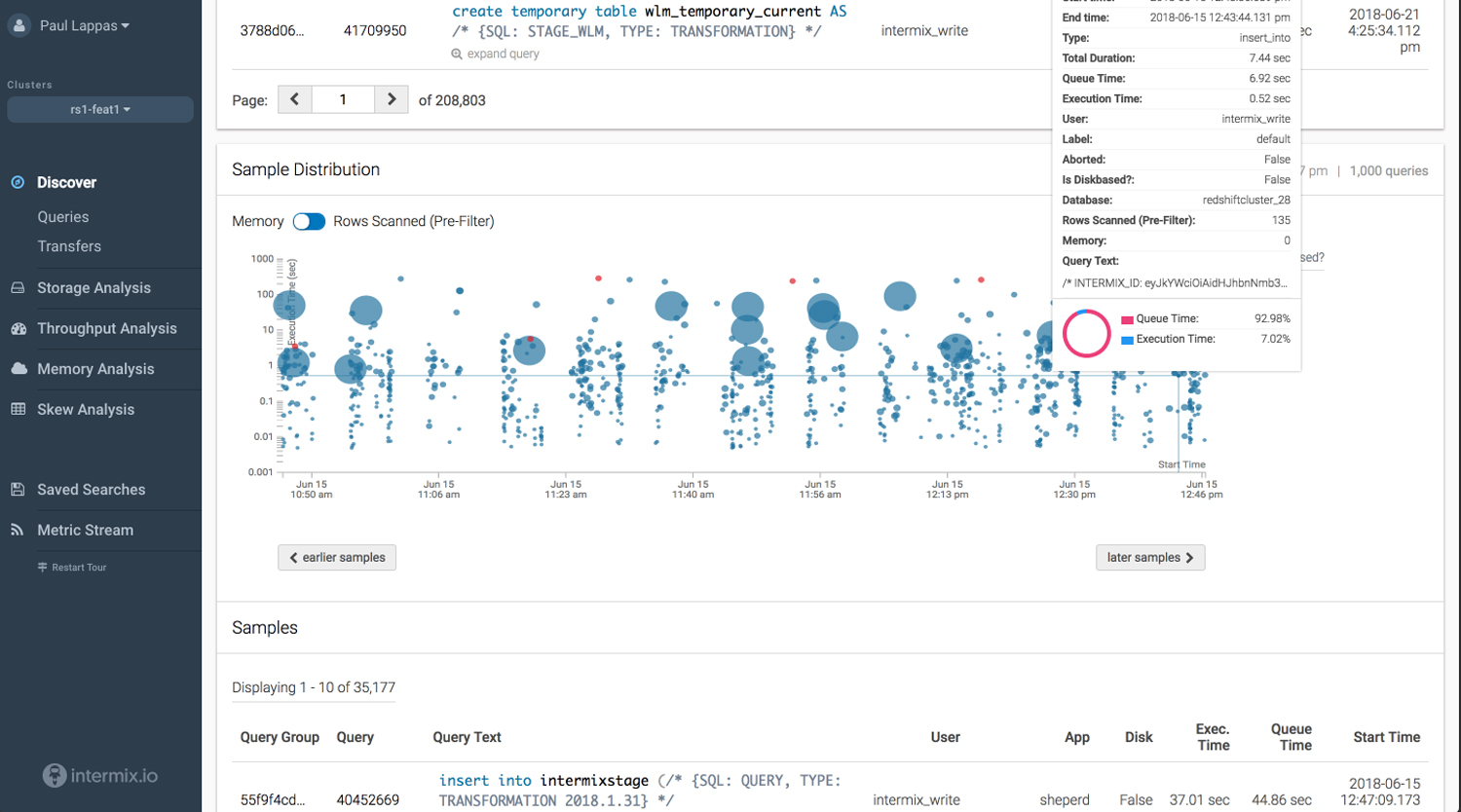
Intermix.io works in a couple of ways: first, it tags all of that data, giving the service a meta-layer of understanding what does what, and where it goes; second, it taps every input in order to gather metrics on performance and help identify those potential bottlenecks; and lastly, it’s able to track that performance all the way from the query to the thing that ends up on a dashboard somewhere. The idea here is that if, say, some server is about to run out of space somewhere or is showing some performance degradation, that’s going to start showing up in the performance of the actual operations pretty quickly — and needs to be addressed.
All of this is an efficiency play that might not seem to make sense at a smaller scale. the waterfall of new devices that come online every day, as well as more and more ways of understanding how people use tools online, even the smallest companies can quickly start building massive data sets. And if that company’s business depends on some machine learning happening in the background, that means it’s dependent on all that training and tracking happening as quickly and smoothly as possible, with any hiccups leading to real-term repercussions for its own business.
Intermix.io isn’t the first company to try to create some application performance management software. There are others like Data Dog and New Relic, though Lappas says that the primary competition from them comes in the form of traditional APM software with some additional scripts tacked on. However, data flows are a different layer altogether, which means they require a more unique and custom approach to addressing that problem.
from Enterprise – TechCrunch https://ift.tt/2lGN6Il
via https://ifttt.com/ IFTTT
No comments:
Post a Comment